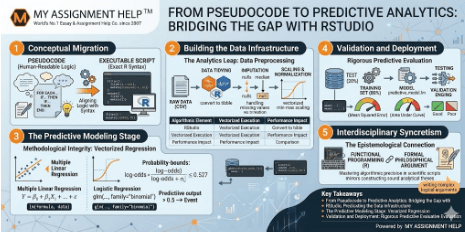
Key Takeaways
- Conceptual Migration: Moving from pseudocode to executable script requires aligning human-readable logic with exact syntax structures.
- The Analytics Leap: RStudio acts as an integrated pipeline that transforms static mathematical algorithms into automated, predictive data models.
- Methodological Integrity: Successful modeling depends on rigorous data tidying, vectorization, and deterministic logic execution.
- Interdisciplinary Syncretism: Technical proficiency in statistical scripts is fundamentally tied to deductive structures used in formal philosophical argumentation.
In modern data science and computer science education across the United States, students face a significant cognitive leap when moving from foundational conceptual algorithms to live, executing scripts. Early coursework emphasizes pseudocode—a non-syntactical, human-readable language designed to map out structural logic, iterative loops, and conditional arguments. While pseudocode isolates logical variables without syntax errors, it lacks the operational power required to handle real-world quantitative structures. To execute advanced statistical data modeling, students must bridge this conceptual blueprint into fully compiled environments.
The transition from abstract planning to active execution finds its strongest tool within the R language ecosystem, controlled through the RStudio Integrated Development Environment (IDE). This shift requires more than learning new syntax; it demands a deep restructuring of how data pipelines, mathematical operations, and predictive calculations interact. Whether you are building an automated predictive regression model or setting up complex analytics frameworks, understanding this migration is essential. For undergraduate and graduate students managing these intricate transformations across top American universities, utilizing specialized r studio assignment help can establish the deep procedural frameworks needed to master algorithmic precision and secure computational clarity.
This technical blueprint explores the strategic shift from structured pseudocode logic to production-ready predictive models within RStudio. We examine data preprocessing rules, vectorization patterns, and predictive evaluation matrices, while contextualizing the logical frameworks that unite empirical software development with formal analytical reasoning.
1. Deconstructing the Architectural Gap
The core tension between pseudocode and functional R programming lies in structural abstraction. Pseudocode assumes infinite memory, generic data collections, and loose typing constraints. A typical algorithmic design might state: FOR each entry in dataset, IF value exceeds threshold, THEN store element. This sequential loop, while simple to read, represents a major bottleneck if written directly into functional statistical computing systems.
R, by design, operates as an interpreted vector language based on functional programming frameworks derived from the S language. In RStudio, processing records through explicit loops (such as for or while statements) is deeply inefficient for large data frameworks due to memory allocation overheads. Instead, RStudio relies heavily on vectorized calculations. This design maps operations across whole numerical structures simultaneously, utilizing underlying compiled C, C++, and Fortran binaries to accelerate processing speeds. Bridging this gap requires translating linear, step-by-step logic into parallel vector math, altering how data shapes are transformed throughout the analytical lifecycle.
2. Building the Vectorized Data Infrastructure
Before launching predictive models, raw unstructured inputs must be transformed into clean, systematic dataframes. Pseudocode often skips these intermediate transformation steps, assuming perfectly uniform data arrays. In practice, data engineering within RStudio requires a strict, step-by-step pipeline focused on data structural integrity, missing-value imputation, and scale normalization.
Using tidyverse libraries (such as dplyr, tidyr, and readr), a raw dataset is read and converted into a tidy tibble framework. This structure ensures every column represents a single variable, and every row represents a distinct observation. Consider the following code block that transitions from conceptual steps to an active tidy pipeline, dealing directly with missing entries through conditional imputation:
R
# RStudio Implementation of Algorithmic Imputation & Normalization
library(dplyr)
library(tidyr)
clean_predictive_frame <- function(raw_data_path) {
raw_data <- read_csv(raw_data_path)
processed_frame <- raw_data %>%
# Remove records missing critical dependent labels
filter(!is.na(target_y)) %>%
# Implement median imputation for continuous independent vectors
mutate(across(where(is.numeric), ~replace_na(., median(., na.rm = TRUE)))) %>%
# Normalize continuous scale via Min-Max transformation
mutate(across(where(is.numeric), ~ ( . – min(.) ) / ( max(.) – min(.) )))
return(processed_frame)
}
This code transforms abstract logical concepts into explicit, executable instructions. Missing data points are fixed using deterministic medians, and numeric values are brought into a shared scale range, preventing wide-scale variations from skewing the predictive weight of the variables.
| Algorithmic Element | Pseudocode Manifestation | RStudio Vectorized Execution | Performance Impact (Big Data) |
| Data Selection | Loop through rows, match text tags | filter(variable == “Criteria”) | Sub-millisecond execution via C++ backend |
| Missing Imputation | Scan vector, replace null entries sequentially | replace_na() or mice() interpolation | Prevents systematic evaluation drops |
| Scale Normalization | Iteratively calculate min/max and modify values | Vectorized evaluation: (x – min) / range | Eliminates memory stacking, preserves matrix size |
| Feature Extraction | Manual calculation of independent terms | recipe() matrix pipelines | Enables repeatable predictive deployments |
3. The Mathematics of Predictive Modeling: Scripting the Logic
Once data shapes are locked into consistent matrices, the transition into predictive analytics relies on solid mathematical frameworks. Unlike pseudocode, which expresses mathematical functions as general equations, RStudio maps out exact statistical limits. Let us look at a standard Multiple Linear Regression model where we predict a continuous variable Y against independent vectors X₁, X₂, … Xₙ. The underlying equation follows this exact structure:
Within this framework, β₀ represents the intercept term, βᵢ denotes the calculated slope coefficient for each variable, and ε maps out the residual error vector. In RStudio, this formula is initialized through the lm() command, which runs Ordinary Least Squares (OLS) calculations to minimize the sum of squared differences between observed and predicted values.
For binary classification models—such as predicting whether a target event will occur or fail—the linear setup is replaced by a Generalized Linear Model (GLM) using a logistic link function. Here, we calculate the log-odds of the probability p using the following expression:
By mapping these functions using the glm(family = “binomial”) syntax, RStudio calculates the probability bounds, returning values between 0 and 1. This mathematical precision bridges simple pseudocode conditional rules (like IF condition THEN probability = high) into exact, clear statistical probabilities.
See also: How Artificial Intelligence Is Used in Smart Homes
4. Validating and Deploying Predictive Scripts
An algorithm is only as reliable as its validation metrics. To ensure models perform well on unseen data, analysts must split the validated dataframe into separate training and testing subsets, typically using an 80/20 partition rule. This prevents overfitting, a common pitfall where a model memorizes random noise within the training data instead of discovering the underlying pattern.
R
# Split Framework and Model Verification Code
set.seed(42) # Ensure random split remains reproducible
sample_size <- floor(0.80 * nrow(clean_predictive_frame))
train_indices <- sample(seq_len(nrow(clean_predictive_frame)), size = sample_size)
train_set <- clean_predictive_frame[train_indices, ]
test_set <- clean_predictive_frame[-train_indices, ]
# Initialize Predictive Model
predictive_model <- lm(target_y ~ feature_x1 + feature_x2, data = train_set)
# Evaluate Test Performance via Mean Squared Error (MSE)
test_predictions <- predict(predictive_model, newdata = test_set)
calculated_mse <- mean((test_set$target_y – test_predictions)^2)
print(paste(“Evaluated Test MSE:”, calculated_mse))
By evaluating the Mean Squared Error (MSE) or checking the Area Under the Receiver Operating Characteristic curve (AUROC), data scientists measure a model’s real-world accuracy. These practices elevate simple programmatic code into robust, scientific predictive environments.
5. The Epistemological Connection: From Algorithmic Code to Formal Argument
The transition from abstract pseudocode to predictive models within RStudio mirrors the structural workflows found in classical analytical philosophy. At its core, writing functional programming scripts relies on deductive and inductive logic. An uncompiled script mirrors an initial philosophical thesis: it sets up a series of defined rules, defines key premises, and expects a true, logical conclusion. When a programmer configures data classes, balances variances, or defines functional parameters, they are engaging in structural truth-mapping akin to symbolic formal deduction.
This logical crossover highlights why STEM and humanities frameworks are deeply connected. Building a complex predictive model follows the exact same cognitive steps required to draft an advanced, multi-layered analytical essay. For students working across these demanding interdisciplinary fields, mastering this structural balance can be incredibly challenging. When balancing code compilation alongside complex humanities requirements, looking for professional insights to write my philosophy paper can help clarify complex logical arguments, ensuring both scientific scripts and written theses remain structurally flawless, highly analytical, and sound.
Conclusion: Transitioning to Advanced Script Engineering
Bridging the gap between pseudocode and predictive analytics in RStudio requires moving past basic syntax memorization to embrace vectorized processing frameworks, clean data engineering, and structured validation methods. Translating abstract steps into production-ready scripts allows analysts to uncover hidden insights within large, complex datasets. As data systems grow more interconnected, mastering these technical paradigms ensures your analytics models remain reproducible, efficient, and scientifically valid.
Frequently Asked Questions (FAQ)
1. Why does RStudio throw memory errors when running standard pseudocode loops?
R is a vectorized language that allocates memory dynamically. Running standard loops requires the system to reallocate memory with every single iteration. This process creates high processing overhead and causes memory crashes on large datasets. Using vectorized functions avoids this problem entirely.
2. What is the best way to handle missing values before running a predictive regression model?
For simple datasets, median or mean imputation prevents records from being dropped. For complex, multi-variable systems, running predictive algorithms like Predictive Mean Matching (PMM) via the mice library delivers superior results without skewing the underlying variance.
3. How can I ensure my RStudio predictive models don’t overfit training data?
Always split your source data using an 80/20 train/test partition, or apply k-fold cross-validation. Monitoring performance metrics across separate validation datasets ensures your model learns real trends instead of memorizing random noise.
About the Author
Dr. Evelyn Vance is a Senior Content Strategist and Academic Research Lead at MyAssignmentHelp. She holds a Ph.D. in Computational Statistics from the University of Texas at Austin and specializes in data engineering workflows, vectorized analytics design, and interdisciplinary logical systems for higher education platforms in the United States.
References and Data Sources
- Wickham, H., & Grolemund, G. (2017). R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. O’Reilly Media.
- Peng, R. D. (2016). R Programming for Data Science. Leanpub Research Series.
- James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning: with Applications in R. Springer Graduate Texts in Mathematics.

 By
By






